
お疲れ様です。きざきまるおです。
今回はSQLを書く上で便利でよく使うファンクションについて紹介しようと思います。
基本的なものではなく、少しニッチな部分になりますので、よかったら見てください。
それではどうぞ。

PostgreSQLインストール
まずは最新版PostgreSQLをインストールするためのリポジトリをインストールしましょう。
dnf install http://apt.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm以下コマンドがインストールコマンドになります。
バージョンは適宜置き換えてください。
dnf install postgresql14-server postgresql14-docs postgresql14-develDBの初期化をします。
/usr/pgsql-14/bin/postgresql-14-setup initdb以下コマンドでPostgreSQLを起動しましょう。
systemctl start postgresql-14テストデータ挿入
まずは確認用DBを作成しましょう。
CREATE DATABASE checkfk;次に動作確認用に5つのテーブルを作成します。
あくまで確認用なのでそれぞれのテーブルに深い意味はありません。
-- usersテーブル
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- productsテーブル
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price INTEGER NOT NULL,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- ordersテーブル
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL REFERENCES users(id),
status VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- order_itemsテーブル
CREATE TABLE order_items (
id SERIAL PRIMARY KEY,
order_id INTEGER NOT NULL REFERENCES orders(id),
product_id INTEGER NOT NULL REFERENCES products(id),
quantity INTEGER NOT NULL,
price INTEGER NOT NULL
);
-- reviewsテーブル
CREATE TABLE reviews (
id SERIAL PRIMARY KEY,
product_id INTEGER NOT NULL REFERENCES products(id),
user_id INTEGER NOT NULL REFERENCES users(id),
rating INTEGER NOT NULL,
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
次に各テーブルへデータを挿入しましょう。
-- usersテーブルにデータを挿入するSQL
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com'),
('Dave', 'dave@example.com'),
('Eve', 'eve@example.com');
-- productsテーブルにデータを挿入するSQL
INSERT INTO products (name, price, description) VALUES
('T-shirt', 1500, 'Comfortable cotton T-shirt'),
('Jeans', 4000, 'High-quality denim jeans'),
('Sneakers', 6000, 'Classic canvas sneakers'),
('Backpack', 3000, 'Durable backpack for everyday use'),
('Watch', 8000, 'Elegant watch with leather strap');
-- ordersテーブルにデータを挿入するSQL
INSERT INTO orders (user_id, status) VALUES
INSERT INTO orders (user_id, status)
VALUES
(1, 'created'),
(2, 'created'),
(3, 'created'),
(4, 'created'),
(5, 'created'),
(1, 'created'),
(2, 'created'),
(3, 'created'),
(4, 'created'),
(5, 'created'),
(1, 'created'),
(2, 'created'),
(3, 'created'),
(4, 'created'),
(5, 'created'),
(1, 'created'),
(2, 'created'),
(3, 'created'),
(4, 'created'),
(5, 'created');
-- order_itemsテーブルにデータを挿入するSQL
INSERT INTO order_items (order_id, product_id, quantity, price)
VALUES
(1, 1, 1, 100),
(1, 2, 2, 200),
(1, 3, 3, 300),
(2, 1, 2, 200),
(2, 2, 3, 300),
(2, 3, 4, 400),
(3, 1, 3, 300),
(3, 2, 4, 400),
(3, 3, 5, 500),
(4, 1, 4, 400),
(4, 2, 5, 500),
(4, 3, 6, 600),
(5, 1, 5, 500),
(5, 2, 6, 600),
(5, 3, 7, 700),
(6, 1, 6, 600),
(6, 2, 7, 700),
(6, 3, 8, 800),
(7, 1, 7, 700),
(7, 2, 8, 800);
-- reviewsテーブルにデータを挿入するSQL
INSERT INTO reviews (product_id, user_id, rating, comment) VALUES
(1, 1, 4, 'This T-shirt is very comfortable.'),
(1, 2, 3, 'The fabric is nice but it runs a bit small.'),
(2, 3, 5, 'These jeans are amazing!'),
(3, 4, 4, 'I wear these sneakers every day.'),
(4, 5, 3, 'The backpack is good quality but the zippers are a bit stiff.'),
(5, 1, 5, 'This watch is perfect for any occasion.'),
(5, 2, 2, 'The leather strap feels cheap.');
これで準備が完了しました。

Window関数
WINDOW関数は、行単位の集計関数を使って、複数の行をグループ化して処理することができる機能です。WINDOW関数を使用することで、データの集計やランキング、移動平均など、SQLで一般的な分析を実行することができます。
WINDOW関数は、OVER句を使って指定された範囲内の行に対して関数を適用します。そのため、通常の集計関数とは異なり、GROUP BY句を使う必要がありません。また、WINDOW関数を使用することで、GROUP BY句を使用する場合に比べて、データの集計やランキングなどの処理が簡単になります。
とりあえず以下SQLの例を見てみましょう。
SELECT
u.name,
oi.price,
RANK() OVER (PARTITION BY u.id ORDER BY oi.price DESC) AS P_RANK,
SUM(oi.price) OVER (PARTITION BY u.id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS P_SUM,
AVG(oi.price) OVER (PARTITION BY u.id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS P_AVG,
LAG(oi.price,1,0) OVER (PARTITION BY u.id ORDER BY oi.price DESC) AS P_LAG,
LEAD(oi.price,1,0) OVER (PARTITION BY u.id ORDER BY oi.price DESC) AS P_LEAD,
(oi.price - AVG(oi.price) OVER (PARTITION BY u.id)) AS P_MINUS_AVG
FROM
order_items oi
JOIN orders o ON oi.order_id = o.id
JOIN users u ON o.user_id = u.id;
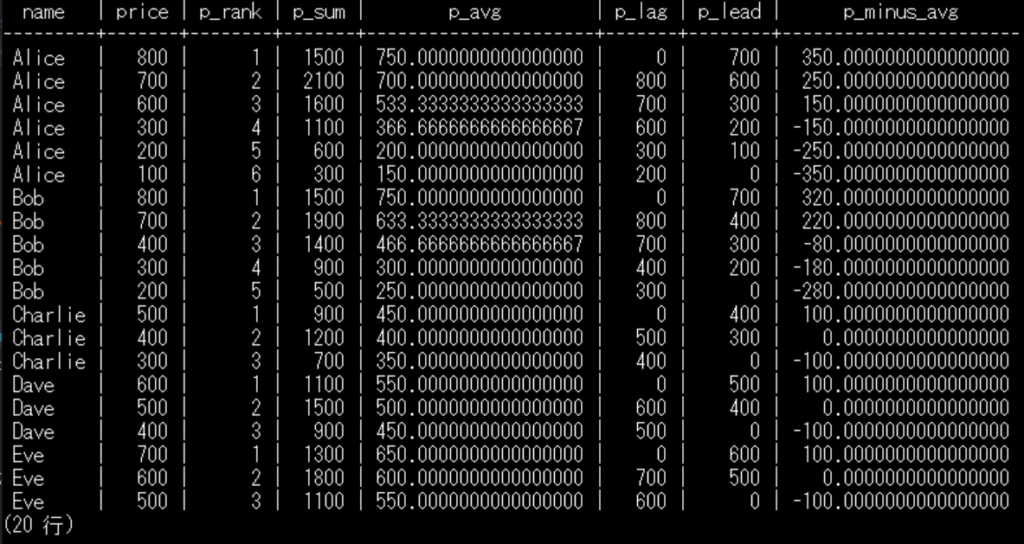
WINDOW関数でよく使われる代表的なものについて説明していきます。
RANK
RANKは、指定された列の値に基づいて、ランキングを計算するための関数です。RANK関数は、同じ値がある場合には同じランクを割り当てますが、スキップランクを使用して、同じランクの場合にランクをスキップすることもできます。
上記SQLはスキップは使用せずにそのままランク付けをしています。
ROWS BETWEEN ~ PRECEDING AND ~ FOLLOWING
ウィンドウフレームは、オーバー関数によって処理される行の範囲を定義するために使用されます。この範囲を定義するために、ROWSまたはRANGEキーワードを使用して、フレームの境界を定義し、その境界を前後に移動する行数を指定します。
上記SQLで指定している「ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING」は、フレームの境界を「現在の行の前の1行から、現在の行の後の1行まで」と定義することを意味します。つまり、現在の行を含めて、前後1行の計3行をウィンドウフレームの範囲に含めます。
LAG
LAG関数は、ウィンドウ内で指定した行数分だけ前の行の値を参照することができます。
他のものと少し肌色が違い、以下のような構文で記載されます。
LAG(column, n, default) OVER (PARTITION BY partition_col ORDER BY order_col)column: LAG関数で参照するカラムを指定します。n: 現在の行から数えて、何行前の値を取得するかを指定します。nには、1以上の整数を指定します。default: もしLAG関数が現在の行よりも前の行がない場合に返す値を指定します。省略可能です。
LEAD
LEAD関数は、ウィンドウ内で指定した行数分だけ後ろの行の値を参照することができます。
LAG関数と同じような構文になります。
LEAD関数は、ウィンドウ内で指定した行数分だけ後ろの行の値を参照することができます。column: LEAD関数で参照するカラムを指定します。n: 現在の行から数えて、何行後ろの値を取得するかを指定します。nには、1以上の整数を指定します。default: もしLEAD関数が現在の行よりも後ろの行がない場合に返す値を指定します。省略可能です。
WITH
WITH句は、一時的なクエリ結果を定義して、後続のクエリで参照できるようにする機能です。よく”Common Table Expressions” (CTE) とも呼ばれます。
WITH句を使用すると、複雑なクエリを実行する際に、一時的なテーブルを作成せずに、複数のクエリで同じ結果を再利用できます。これにより、クエリの可読性が向上し、コードの再利用性が高まります。
SQL例は以下になります。
WITH product_reviews AS (
SELECT p.id, p.name, r.comment
FROM products p
INNER JOIN reviews r ON p.id = r.product_id
)
SELECT pr.id, pr.name, pr.comment
FROM product_reviews pr;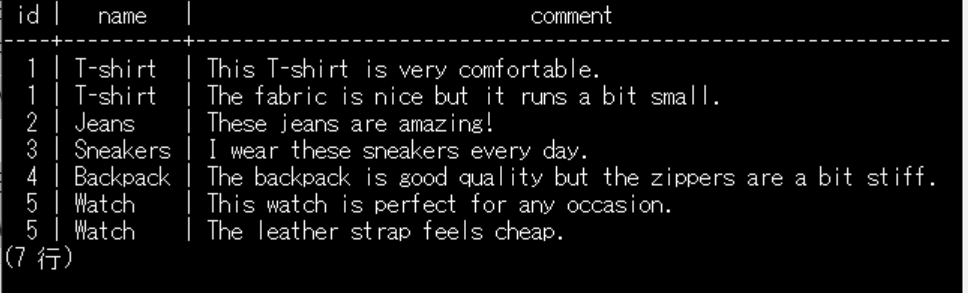
WITH句で作成した「product_reviews」をSELECT文で呼び出すと問題なく結果が表示されるようになります。
WITH句が輝く3ケースを見てみましょう
サブクエリでの利用
WITH product_reviews AS (
SELECT p.id AS product_id, p.name AS product_name, r.rating, r.comment
FROM products p
JOIN reviews r ON p.id = r.product_id
)
SELECT *
FROM products
WHERE id IN (
SELECT product_id
FROM product_reviews
WHERE rating >= 4
);
はい、ということでWITH句で作成した「product_reviews」をサブクエリの中で使用しても問題なく表示することができました。
このようにSQL本文の前に指定しておくことで可読性が向上するのが期待できますね。
複雑なクエリの分割
WITH order_items_summary AS (
SELECT
order_id,
SUM(quantity) AS total_quantity,
SUM(price) AS total_price
FROM order_items
GROUP BY order_id
),
orders_summary AS (
SELECT
orders.id,
orders.user_id,
orders.status,
orders.created_at,
order_items_summary.total_quantity,
order_items_summary.total_price
FROM orders
JOIN order_items_summary
ON orders.id = order_items_summary.order_id
)
SELECT
orders_summary.id,
users.name AS user_name,
products.name AS product_name,
orders_summary.total_quantity,
orders_summary.total_price
FROM orders_summary
JOIN users ON orders_summary.user_id = users.id
JOIN order_items ON orders_summary.id = order_items.order_id
JOIN products ON order_items.product_id = products.id;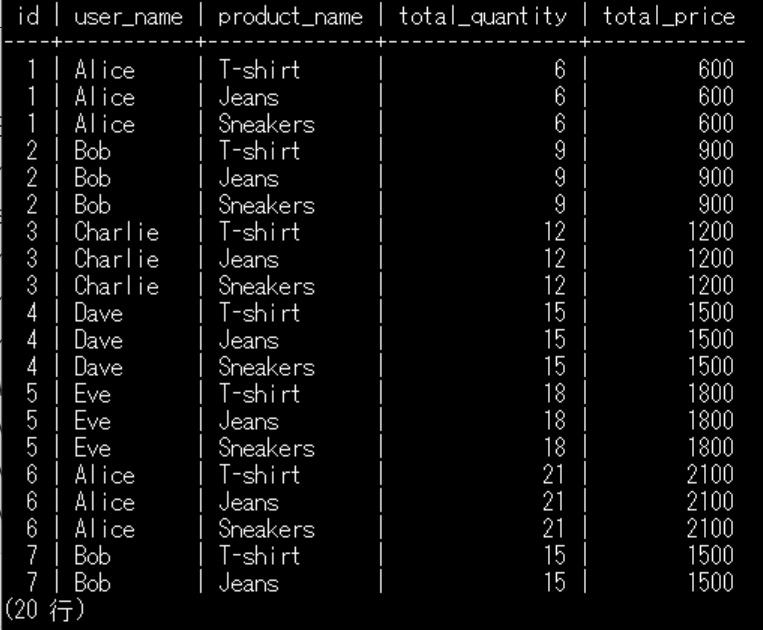
SQL文もかなり複雑なものとなっていますが、WITH句を使うことで本文がかなりすっきりしています。
再帰クエリ
WITH RECURSIVE句は、PostgreSQLなどのリレーショナルデータベースで再帰的なクエリを実行するために使用される構文です。WITH RECURSIVE句を使用することで、複数のテーブルを結合せずに、1つのクエリで自己参照的なテーブルを構築できます。
WITH RECURSIVE user_tree AS (
SELECT id, name, email, NULL::INTEGER AS parent_id, 0 AS level
FROM users
WHERE id = 1
UNION ALL
SELECT u.id, u.name, u.email, ut.id, ut.level + 1
FROM users u
JOIN user_tree ut ON ut.id = u.id
WHERE ut.level < 2
)
SELECT id, name, email, parent_id, level
FROM user_tree;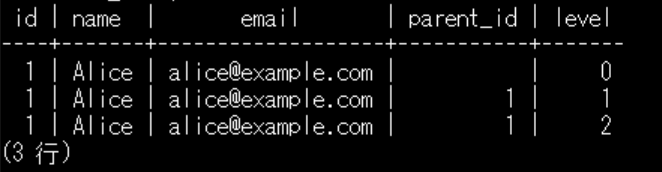
自分自身を呼び出すことが出来るので、SQL本文でごちゃごちゃ書くよりもこちらのほうが整理しやすくなります。
今回紹介しきれなかったファンクションもあるので、それはまたいつか書こうと思います。
それではまた。
